定义数据库模型
在开发插件时,你可能需要定义自己的数据库模型来存储和管理数据。g0v0 使用 SQLAlchemy + SQLModel 来处理数据库操作;使用包装过的 Alembic 来处理数据库迁移。
新建数据库模型
要定义一个新的数据库模型,你需要在插件的 __init__.py 文件中创建一个继承自 DatabaseModel 的类。例如,假设你的插件 ID 是 my_plugin,你可以这样定义一个新的数据库模型:
from app.database._base import DatabaseModel
from sqlmodel import Field
class MyPluginModel(DatabaseModel, table=True):
__tablename__ = "mytable" # -> plugin_my_plugin_mytable
id: int = Field(primary_key=True)
name: str = Field(max_length=255, nullable=False)在上面的示例中,我们定义了一个名为 MyPluginModel 的数据库模型,它有两个字段:id 和 name。__tablename__ 属性指定了数据库表的名称,g0v0 会自动将插件 ID 作为前缀,以避免与其他插件或核心数据库表发生冲突。
DatabaseModel 使用起来与 SQLModel 无异,你可以使用所有 SQLModel 支持的功能来定义你的数据库模型。但是它加了以下两点特性:
- dump 为 JSON 时会自动将 datetime 对象转换为 ISO 格式的字符串,且时区为 UTC。这样解决了 MySQL 内置
DATETIME类型不支持时区的问题。 - 在 dump 时控制输出的字段,详情见下面的控制输出字段与动态计算字段。
数据库迁移
定义好数据库模型后,你需要创建一个数据库迁移文件来将模型应用到数据库中。我们提供了 g0v0-migrate 命令行工具来帮助你创建和管理数据库迁移。它的用法基本和 Alembic 一致。不同的是,你需要在插件目录下运行命令。它会自动产生独立于核心数据库和其他插件迁移历史的迁移脚本并将其放在插件的 migrations/ 文件夹中。
cd plugins/my_plugin
g0v0-migrate revision -m "Create my_plugin_mytable" --autogenerate
g0v0-migrate upgrade head实现原理
参考 #97
使用
定义好数据库模型并完成迁移后,你就可以在插件的其他部分使用这个模型了。例如,你可以在 API 端点中使用它来处理数据库操作:
from app.dependencies.database import Database
from app.plugins import register_api
router = register_api()
@router.post("/items/")
async def create_item(db: Database):
item = MyPluginModel(name="Example Item")
db.add(item)
await db.commit()
await db.refresh(item)
return item控制输出字段与动态计算字段
DatabaseModel 的强大之处在于你可以在庞大的数据库模型中控制输出的字段,避免泄露敏感信息或减少不必要的数据传输。
实现原理
参考这篇博客文章:在 SQLModel 下的一种按需返回的设计
字段类型与模型定义结构
在这个机制下,字段拥有四种类型:
- 普通字段:默认类型,既可以存储数据,也会被输出。
- 计算字段:不存储数据,而是通过一个方法动态计算得出。
- 普通按需字段:默认不输出,只有在调用
Model.transform()时显式指定才会被输出。 - 计算按需字段:既不存储数据,也不会被输出,只有在调用
Model.transform()时显式指定才会被输出。
你可以查看下面的实例代码来了解如何定义这些字段:
from typing import TypedDict, NotRequired
from app.database._base import DatabaseModel, OnDemand, included, ondemand
from sqlmodel import Field
from sqlmodel.ext.asyncio.session import AsyncSession
class DataDict(TypedDict):
id: int
name: str
name_length: int
secret_info: NotRequired[str]
secret_info_length: NotRequired[int]
class DataModel(DatabaseModel[DataDict]):
__tablename__ = "mytable"
# 普通字段
id: int = Field(primary_key=True)
name: str = Field(max_length=255, nullable=False)
# 计算字段,使用 `@included` 装饰器标记,表示它会被默认输出
@included
@staticmethod
async def name_length(_session: AsyncSession, data: "Data") -> int:
return len(data.name)
# 普通按需字段,使用 `OnDemand` 类型标记,表示它默认不输出,只有在调用 `transform()` 时显式指定才会被输出
secret_info: OnDemand[str] = Field(max_length=255, nullable=False)
# 计算按需字段,使用 `@ondemand` 装饰器标记,表示它既不存储数据,也不会被输出,只有在调用 `transform()` 时显式指定才会被输出
@ondemand
@staticmethod
async def secret_info_length(_session: AsyncSession, data: "Data") -> int:
return len(data.secret_info)
class Data(DataModel, table=True):
...同时你还会注意到我们使用了 Dict - Model - Table 三层结构来定义数据库模型。这是为了更好地支持按需字段的类型提示和数据验证。你可以:
- 使用
Dict来对输出结果进行类型提示 - 使用
Model来定义数据库模型的逻辑结构 - 使用
Table来处理数据库表的映射关系和关联关系
警告
使用 OnDemand 需要将整个类型包裹在 OnDemand 中,不要将 OnDemand 与 Union 等其他类型混用,否则可能会导致类型提示和数据验证出现问题。
# 错误示例
secret_info: OnDemand[str] | None = Field(max_length=255, nullable=False)
# 正确示例
secret_info: OnDemand[str | None] = Field(max_length=255, nullable=False)转换数据
你可以使用 Model.transform() 方法来转换数据并控制输出的字段。例如:
data = await db.get(Data, 1)
# 默认只输出普通字段和计算字段
print(Data.transform(data))
# 输出 `secret_info` 字段
print(Data.transform(data, includes=["secret_info"]))计算上下文和嵌套 include
计算字段和按需字段的方法支持传入参数,这些参数可以在计算过程中使用。例如:
@included
@staticmethod
async def name_length(
_session: AsyncSession,
data: "Data",
multiplier: int = 1
) -> int:
return len(data.name) * multiplier在 transform() 方法中,你需要通过传入 multiplier 参数来传入上下文:
data = await db.get(Data, 1)
print(Data.transform(
data,
includes=["name_length"],
multiplier=2,
)
)你还可以在计算字段中使用 transform() 方法来实现嵌套 include。只需要再接受一个 includes 参数并传入到 transform() 方法中即可:
@included
@staticmethod
async def sub_table(session: AsyncSession, data: "Data", includes: list[str] = []) -> list[SubDataDict]:
sub_data_list = await session.query(SubData).filter(SubData.data_id == data.id).all()
return [SubData.transform(sub_data, includes=includes) for sub_data in sub_data_list]在 Pydantic 和 API 文档中使用
当你需要使用 Pydantic 的 TypeAdapter 来对数据进行类型验证时,你需要使用 Model.generate_typeddict() 方法来生成一个包含按需字段的 TypedDict 类型。例如:
from pydantic import TypeAdapter
DataDictAdapter = TypeAdapter(Data.generate_typeddict(includes=["secret_info"]))同样地,你也可以将这个 TypedDict 类型用在 FastAPI 的 API 文档中:
@router.get(
"/data/{data_id}",
response_model=Data.generate_typeddict(includes=["secret_info"])
)
async def get_data(data_id: int, db: Database):
data = await db.get(Data, data_id)
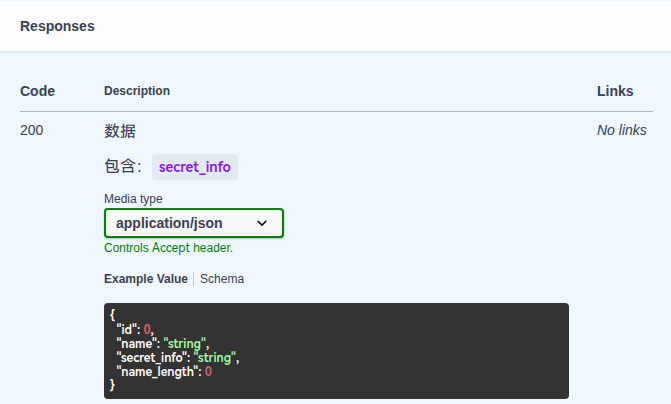
return Data.transform(data, includes=["secret_info"])对于这种情况,g0v0 还提供了一个快捷方式,你可以使用 api_doc 这个辅助函数来对模型进行包装,它会自动调用 generate_typeddict() 并将 include 输出到响应描述中。
from app.utils import api_doc
@router.get("/data/{data_id}",
responses={
200: api_doc(
desc="数据",
model=DataModel,
includes=["secret_info"],
name="DataResponse",
)
}
)
async def get_data(data_id: int, db: Database):
data = await db.get(Data, data_id)
return Data.transform(data, includes=["secret_info"])在 Swagger UI 中,显示如下: